
What Inception Net Doesn't See
Deep learning vision models like Inception Net achieve state-of-the-art performance on image recognition. However, I’m curious about when these models don’t work well. I tested Inception Net on a large number of natural images, and here is a collection of things that the model doesn’t predict well. Note: I’m only including examples where the correct class is one of the 1,000 valid ImageNet classes.
Try it Yourself: Along with each example is a link to the model demo (built with Gradio) where you can try the image yourself directly from the browser.
1. Upside down cars
- Inception Net doesn’t recognize the car category at all when the car is upside down
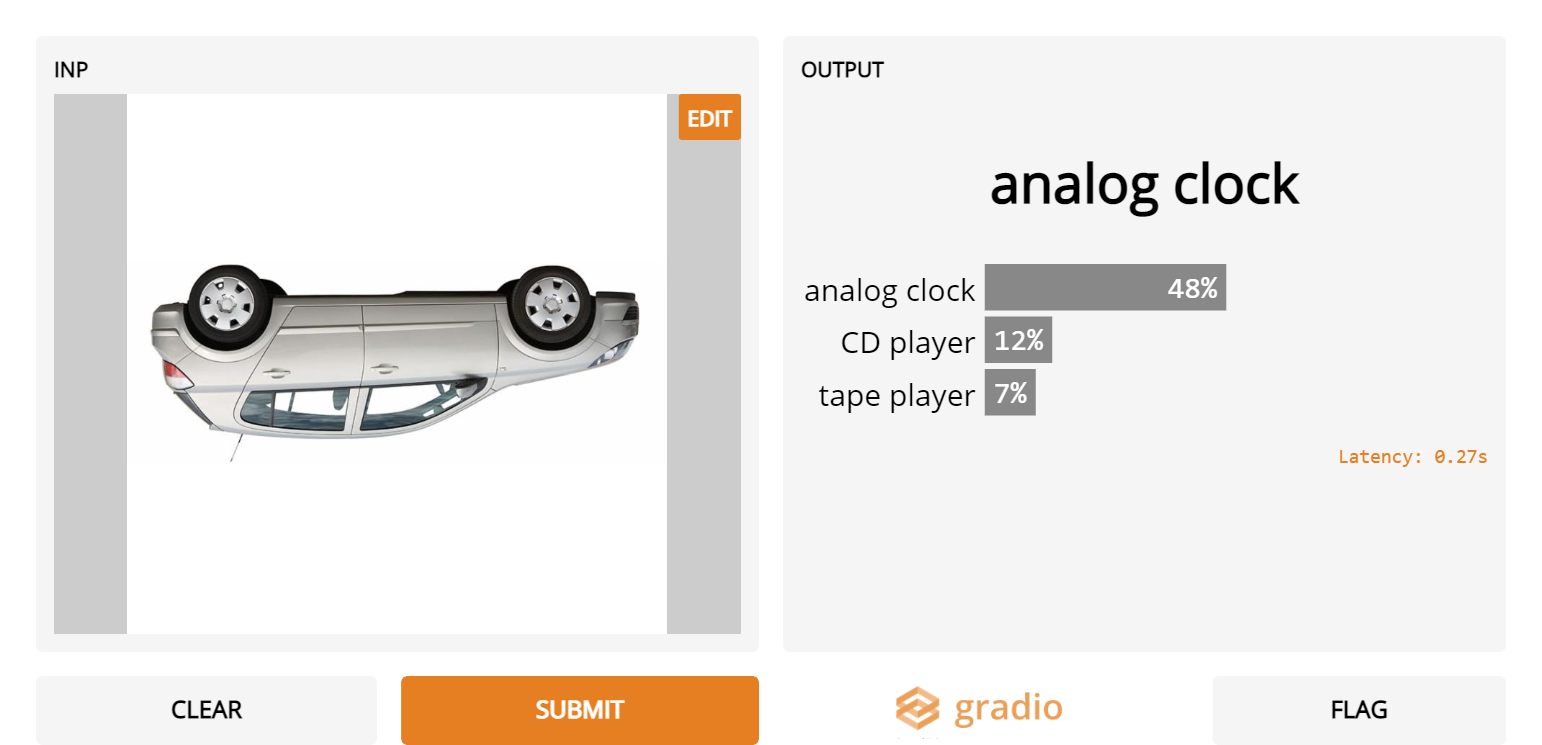
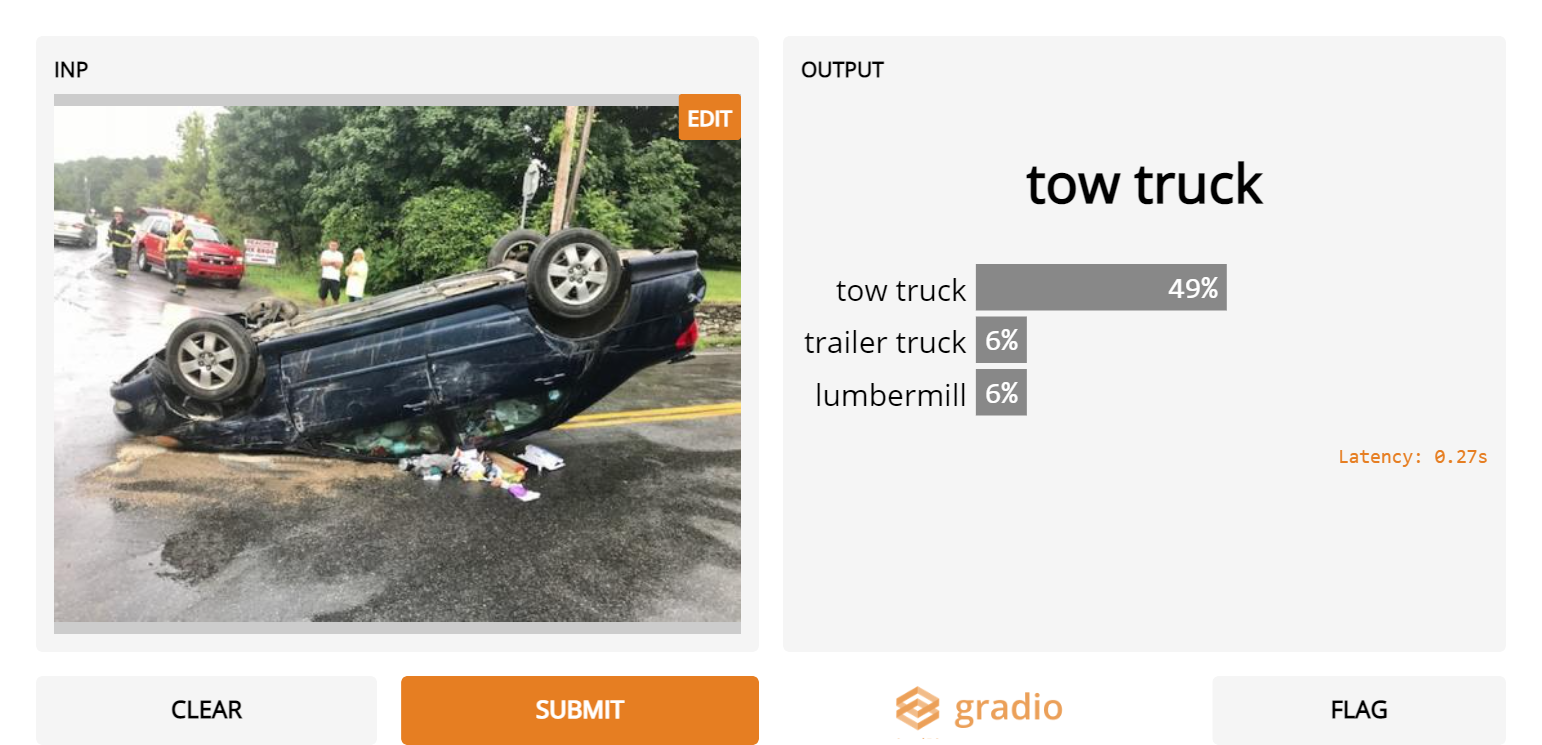
2. Sliced apples
- Although Inception Net recognizes many sliced fruits, it is convinced that sliced apples are actually cucumbers or other fruits.
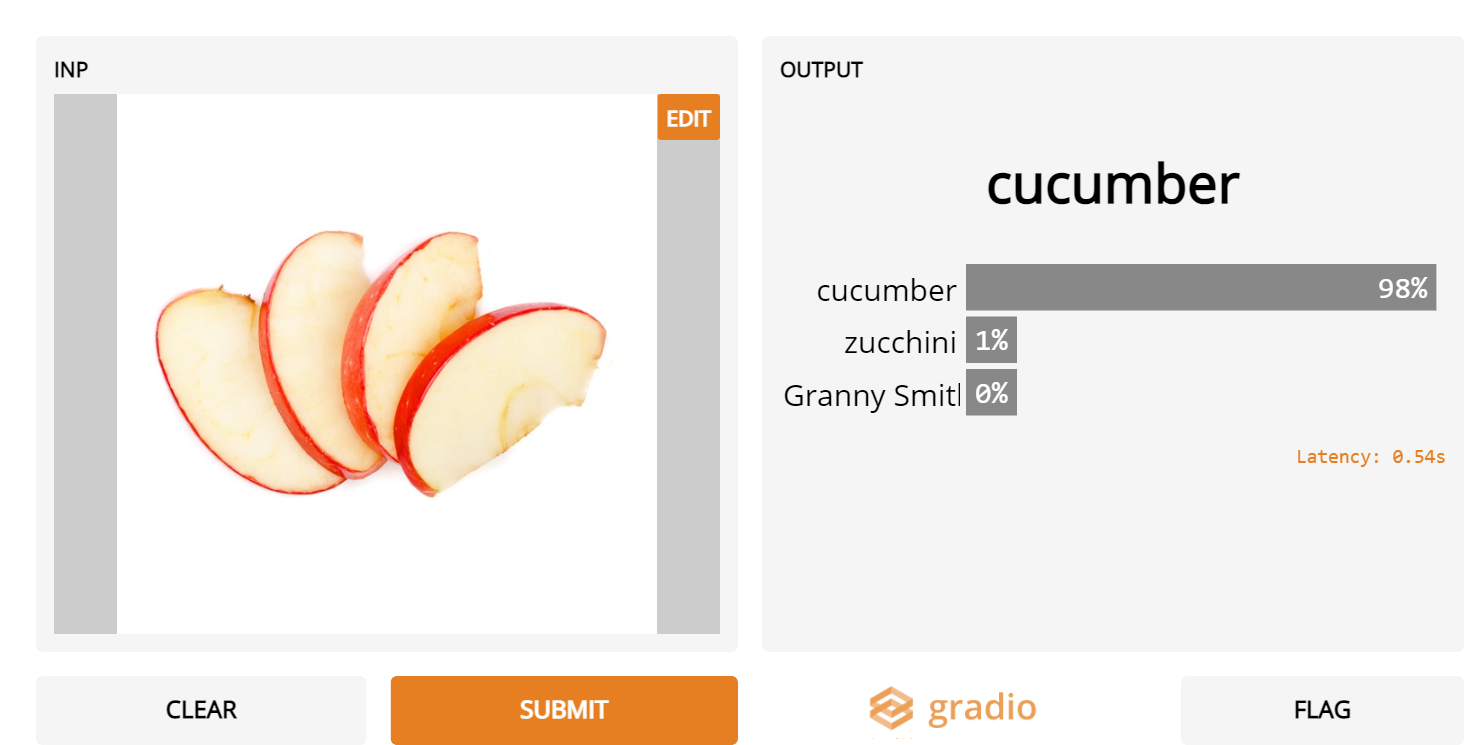
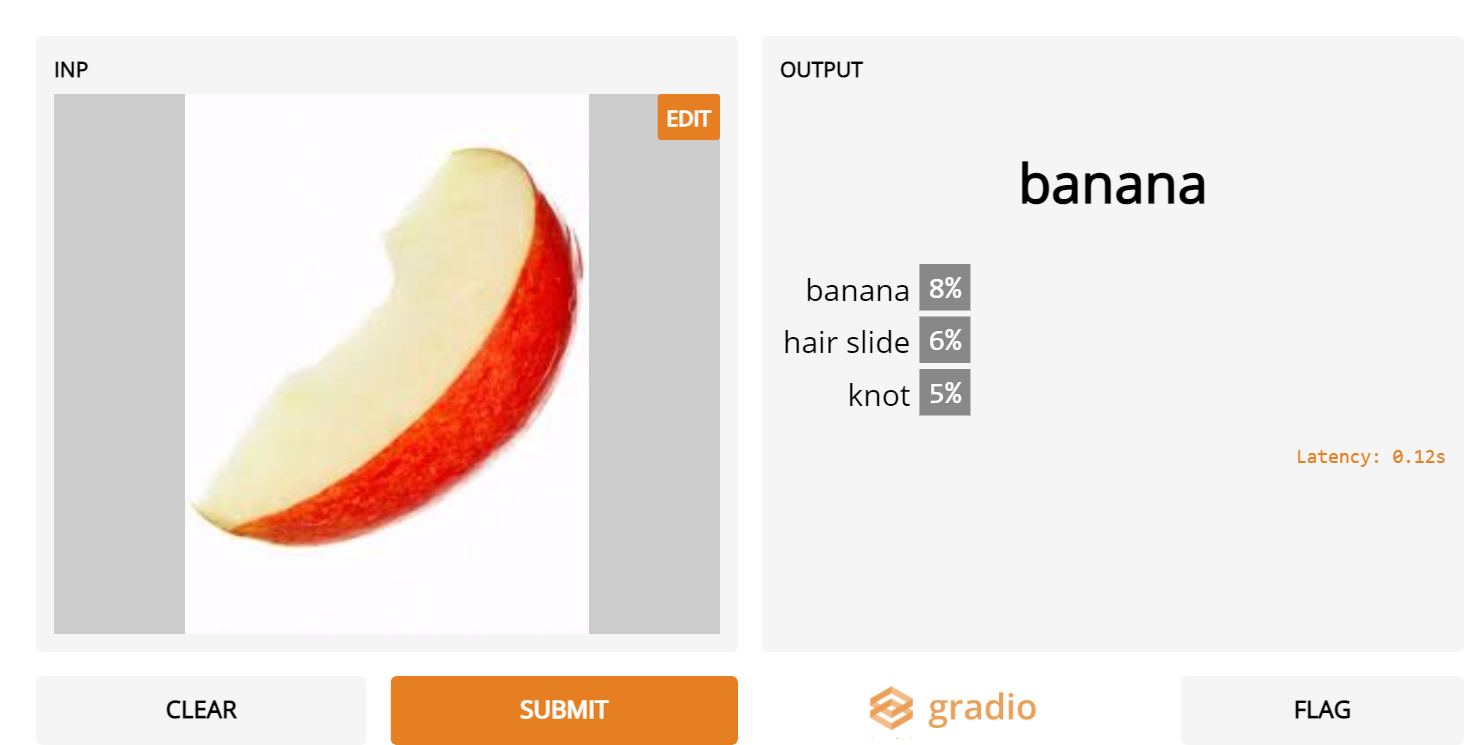
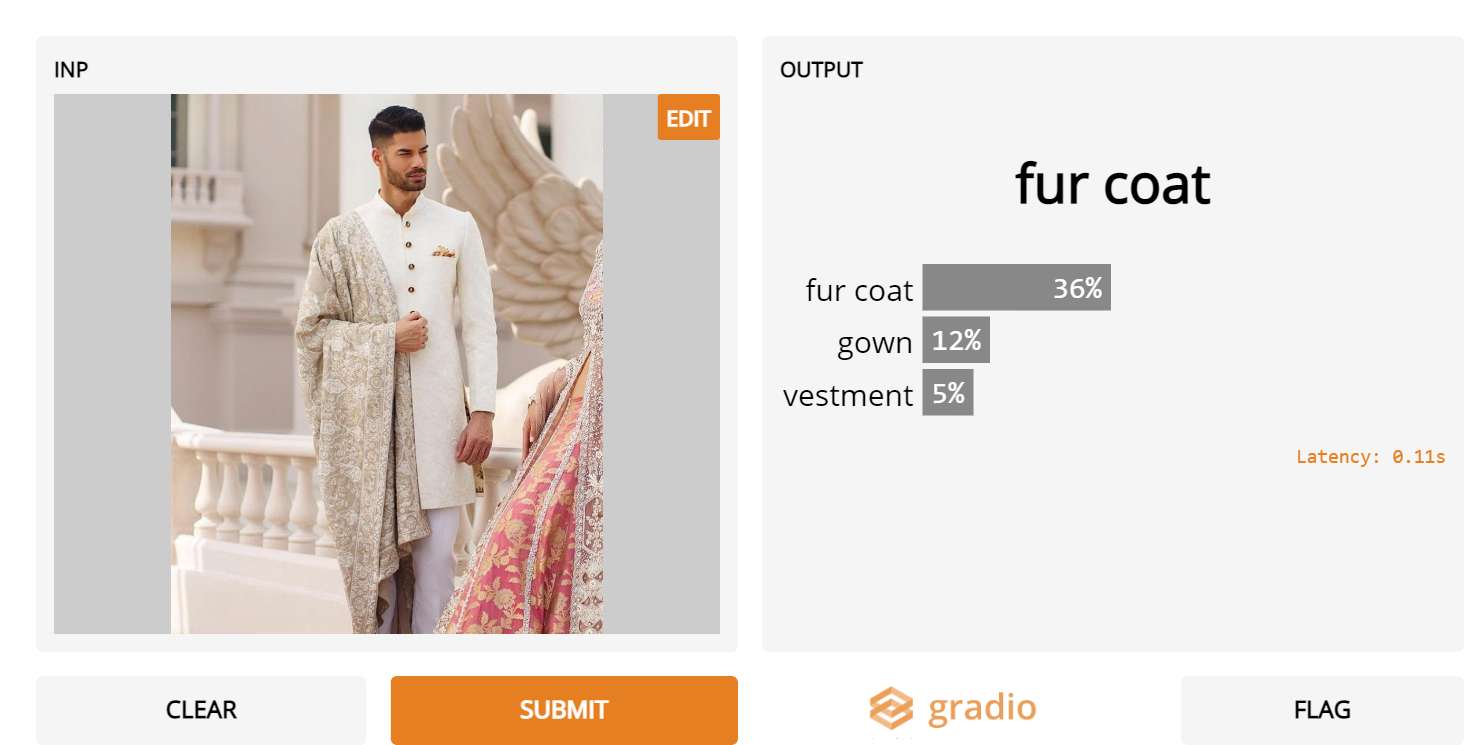
3. Pakistani grooms
- Inception Net can detect Western-dressed grooms quite well, but not when they’re wearing Pakistani / Indian attire
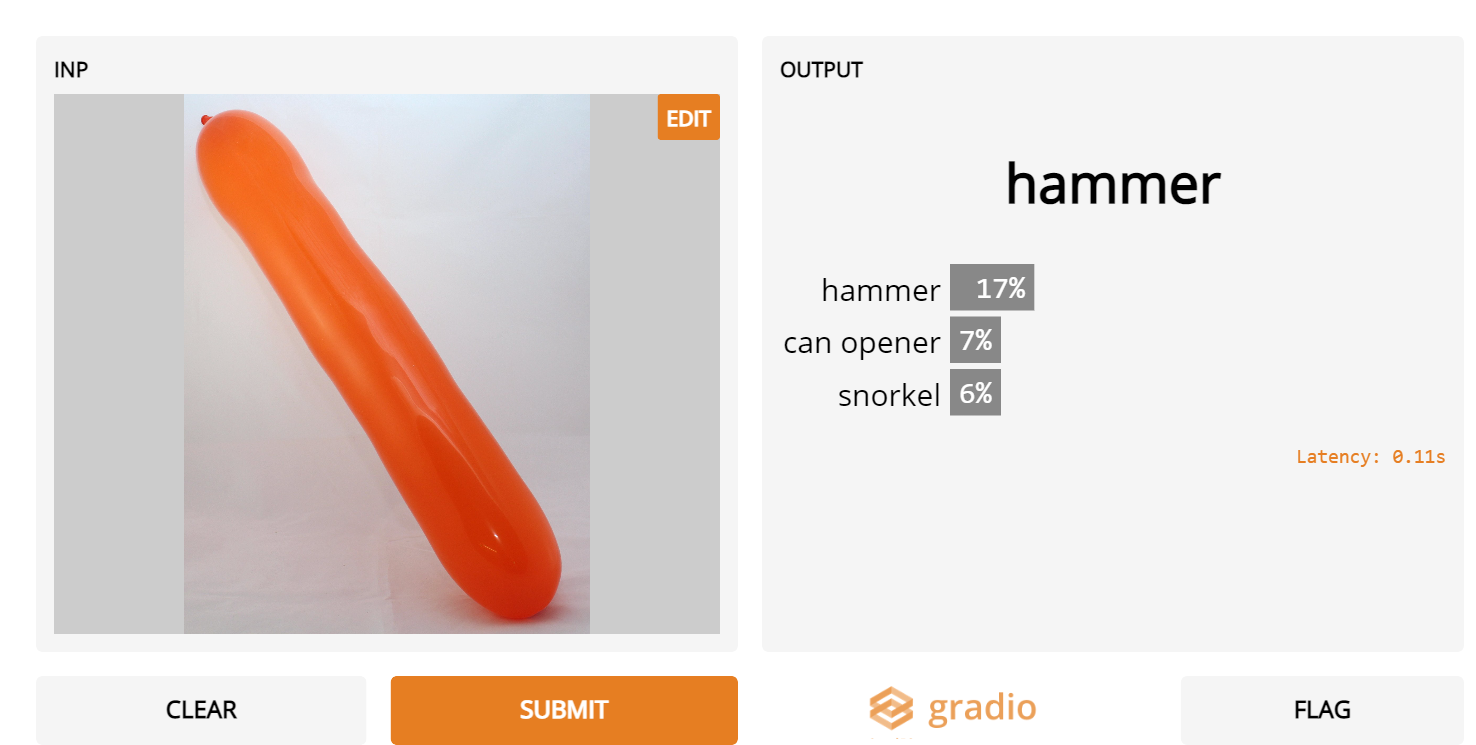
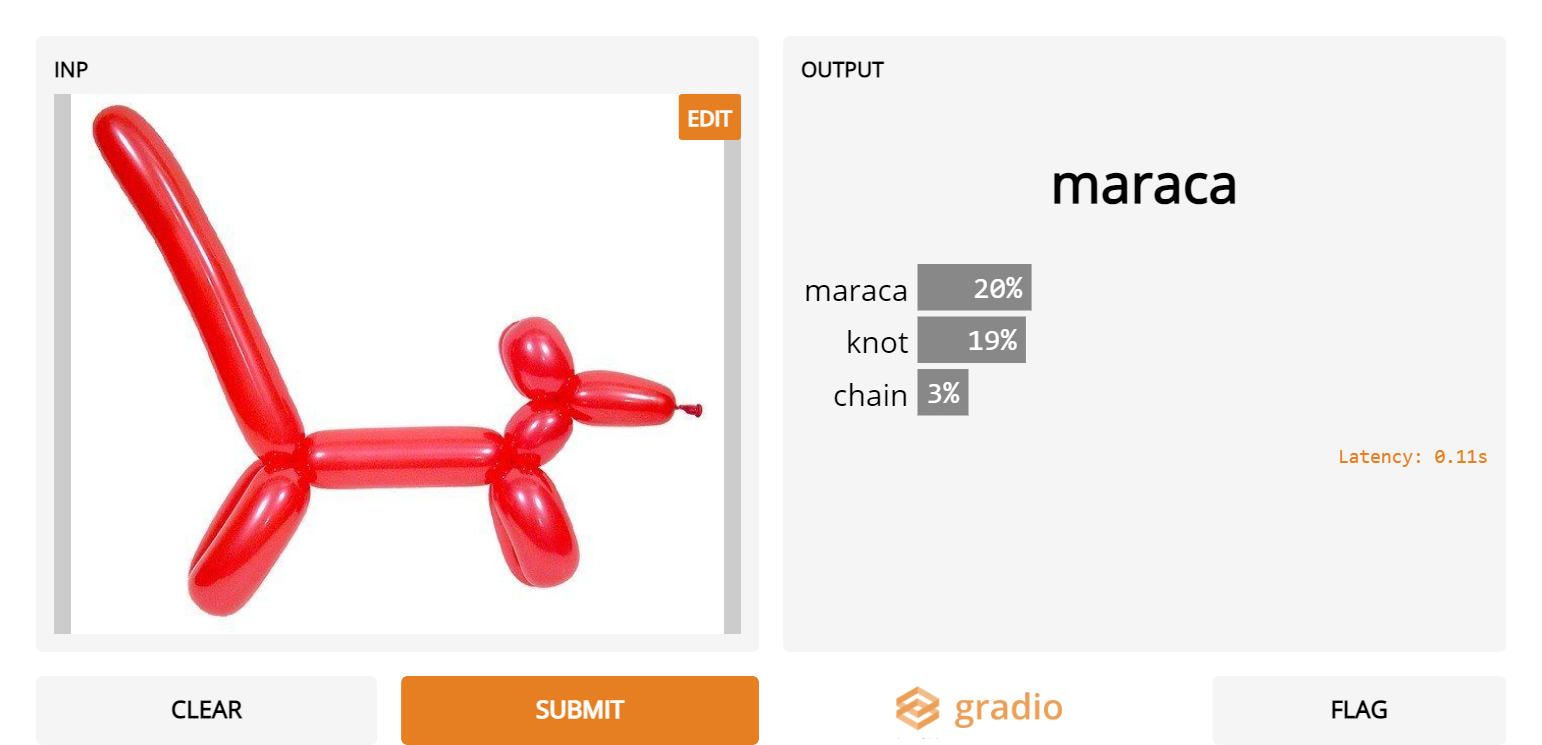
4. Long balloons
- “If it isn’t round, it isn’t a balloon” – Inception Net
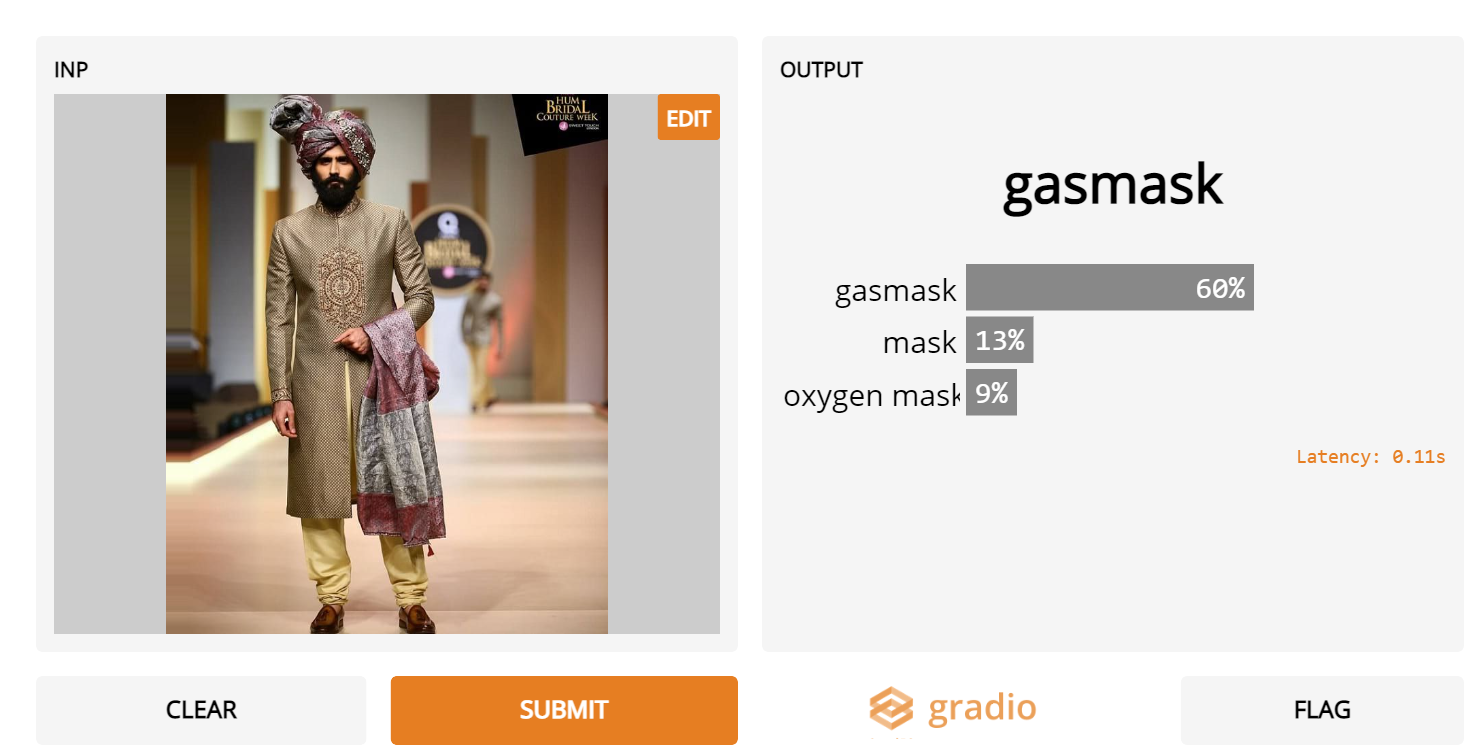
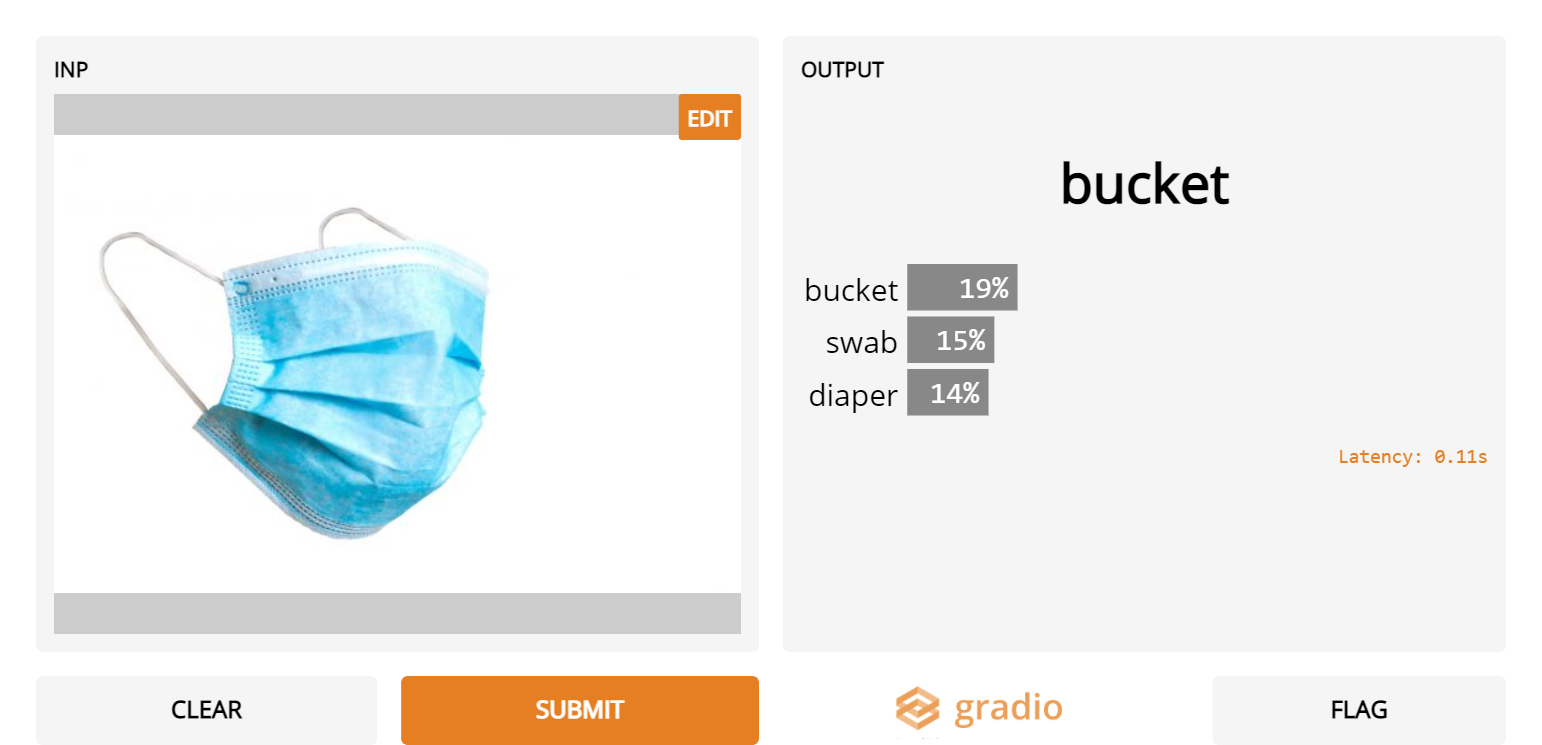
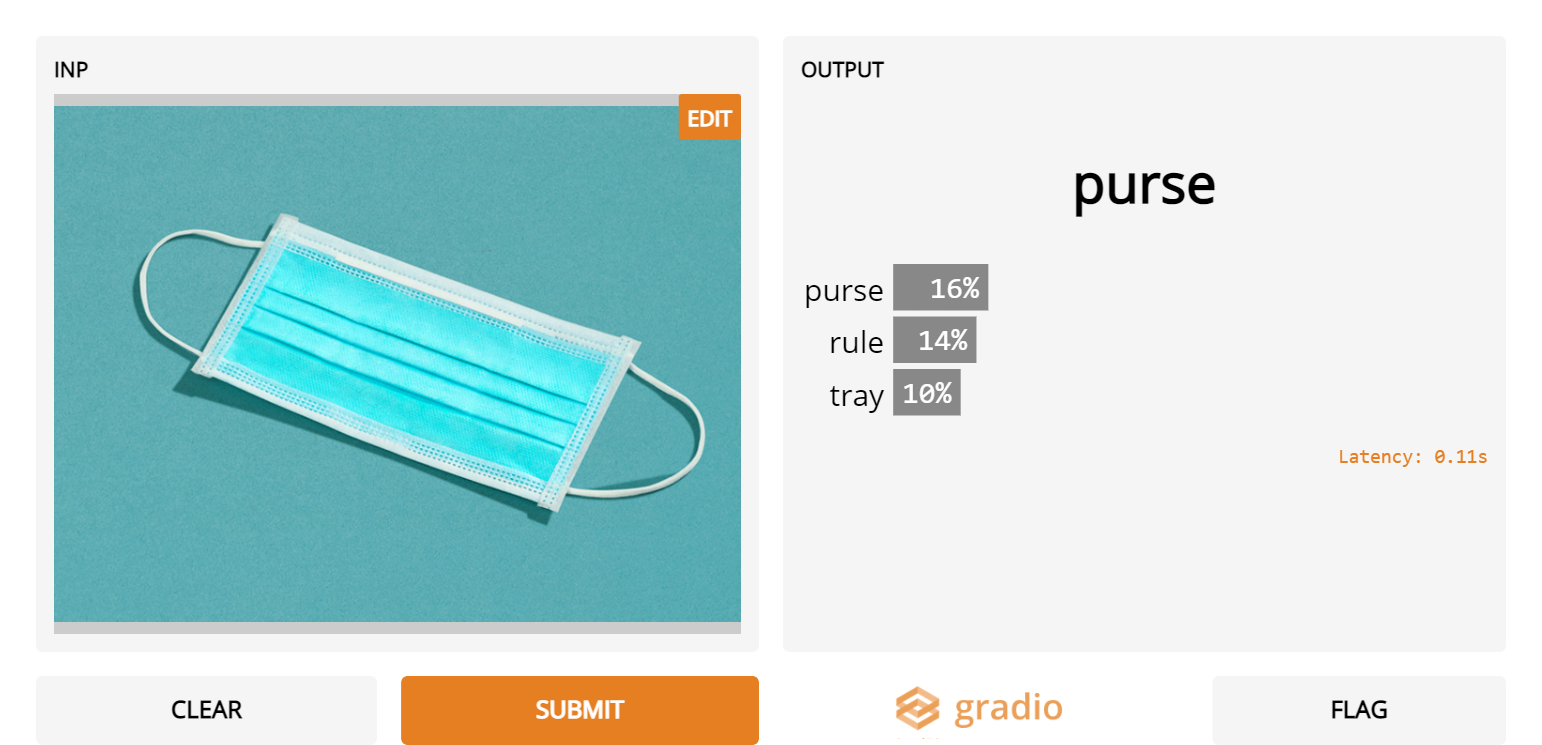
5. Regular surgical masks
- Admittedly, ImageNet was collected way before COVID-19, when these were less common. However, it’s strange that even though masks and gas masks are valid categories, they are not predicted for regular surgical masks.
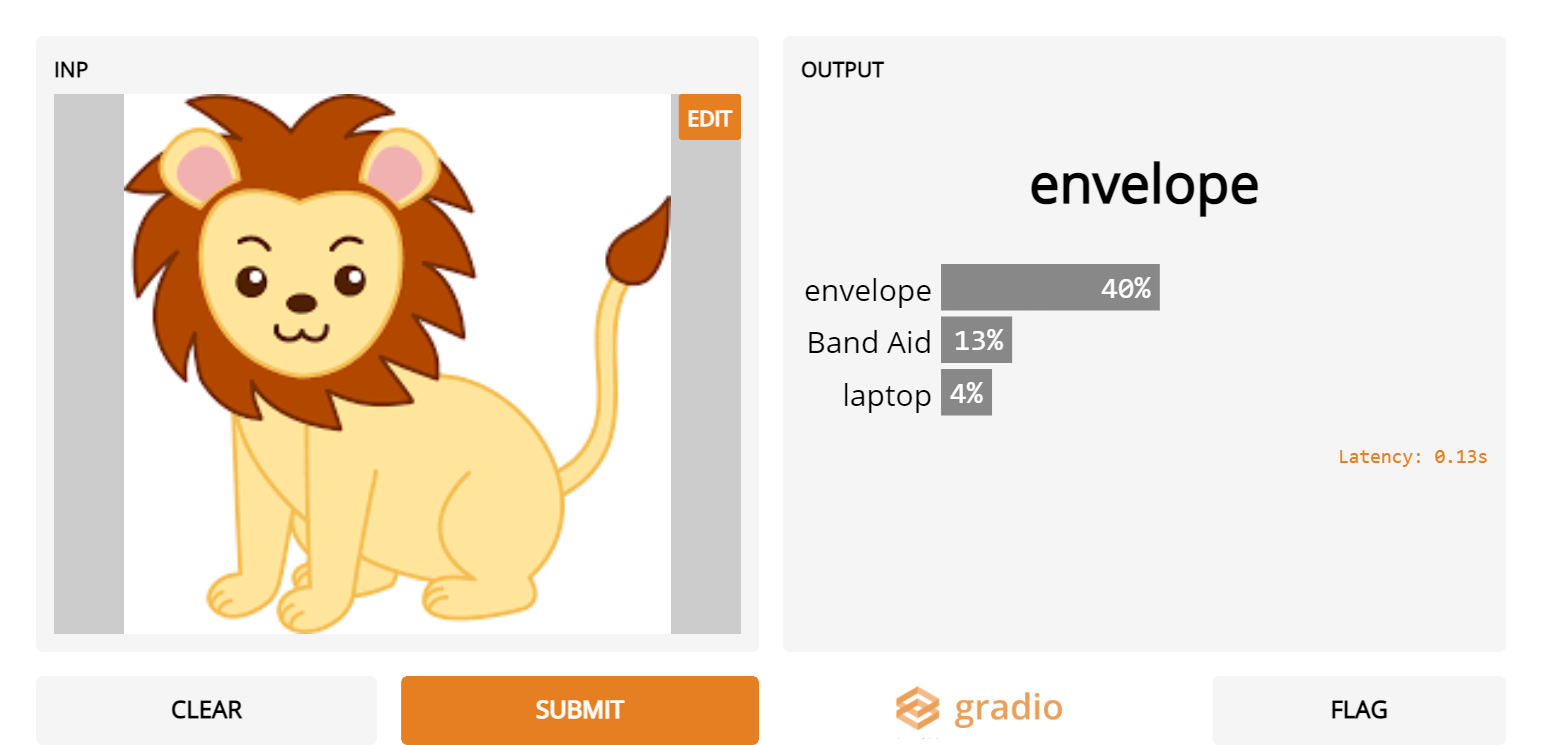
6. Cartoon lions
- Generally Inception Net fails at classifying cartoon versions of images. In my experience, cartoon lions were particularly hard for it to classify correctly.

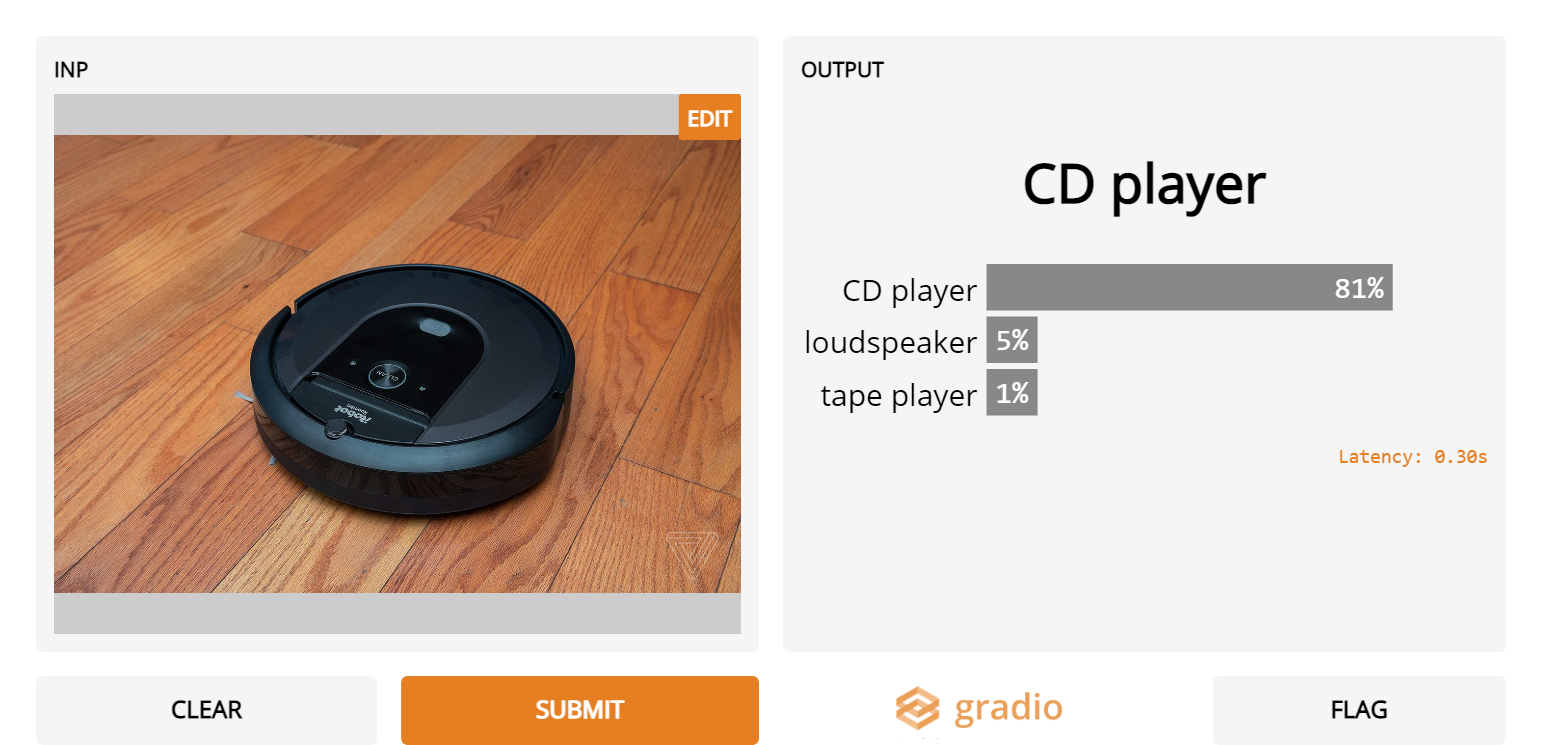
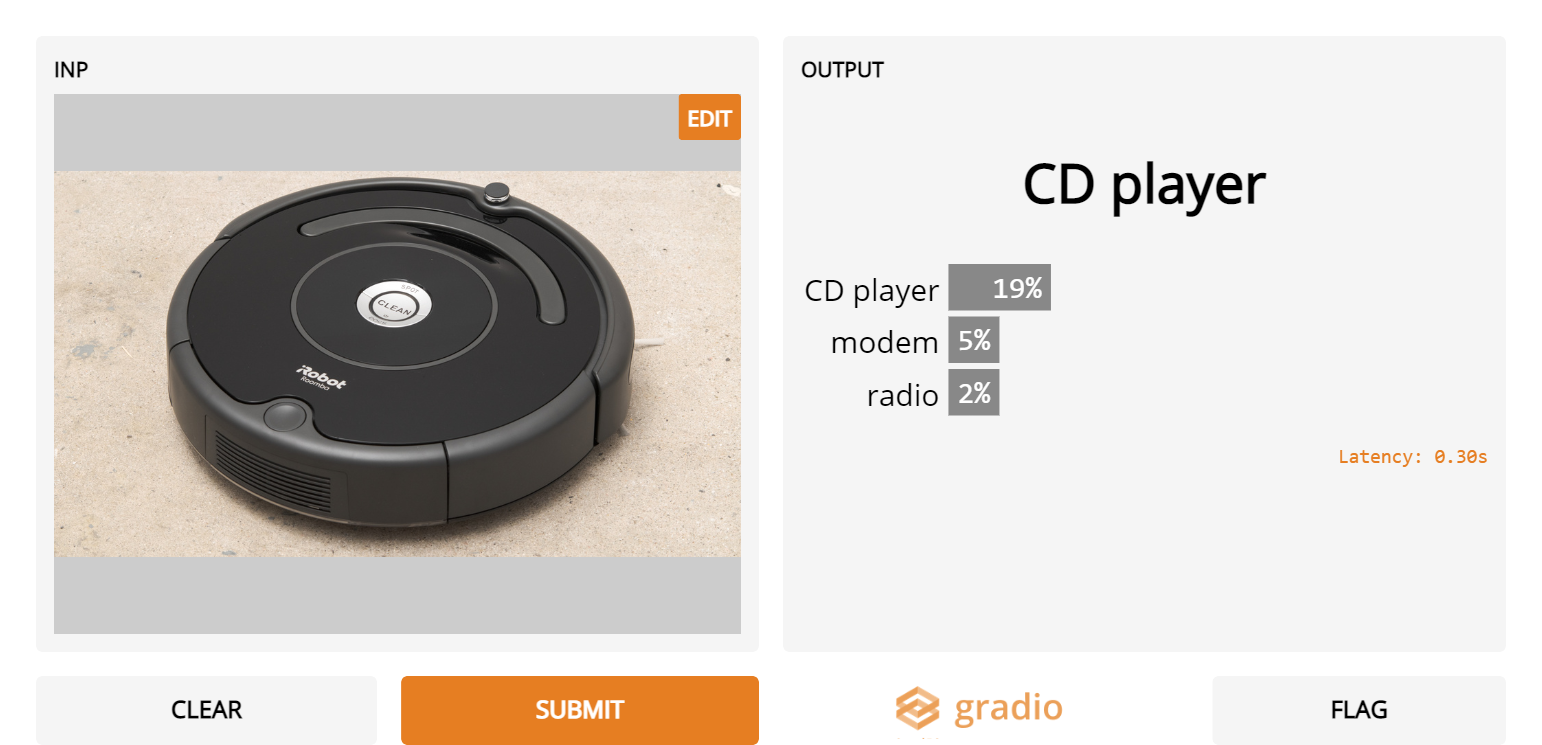
7. Roombas
- It looks like Inception Net doesn’t know about the Roomba vacuum cleaner as it consistently misidentifies it as another gadget instead
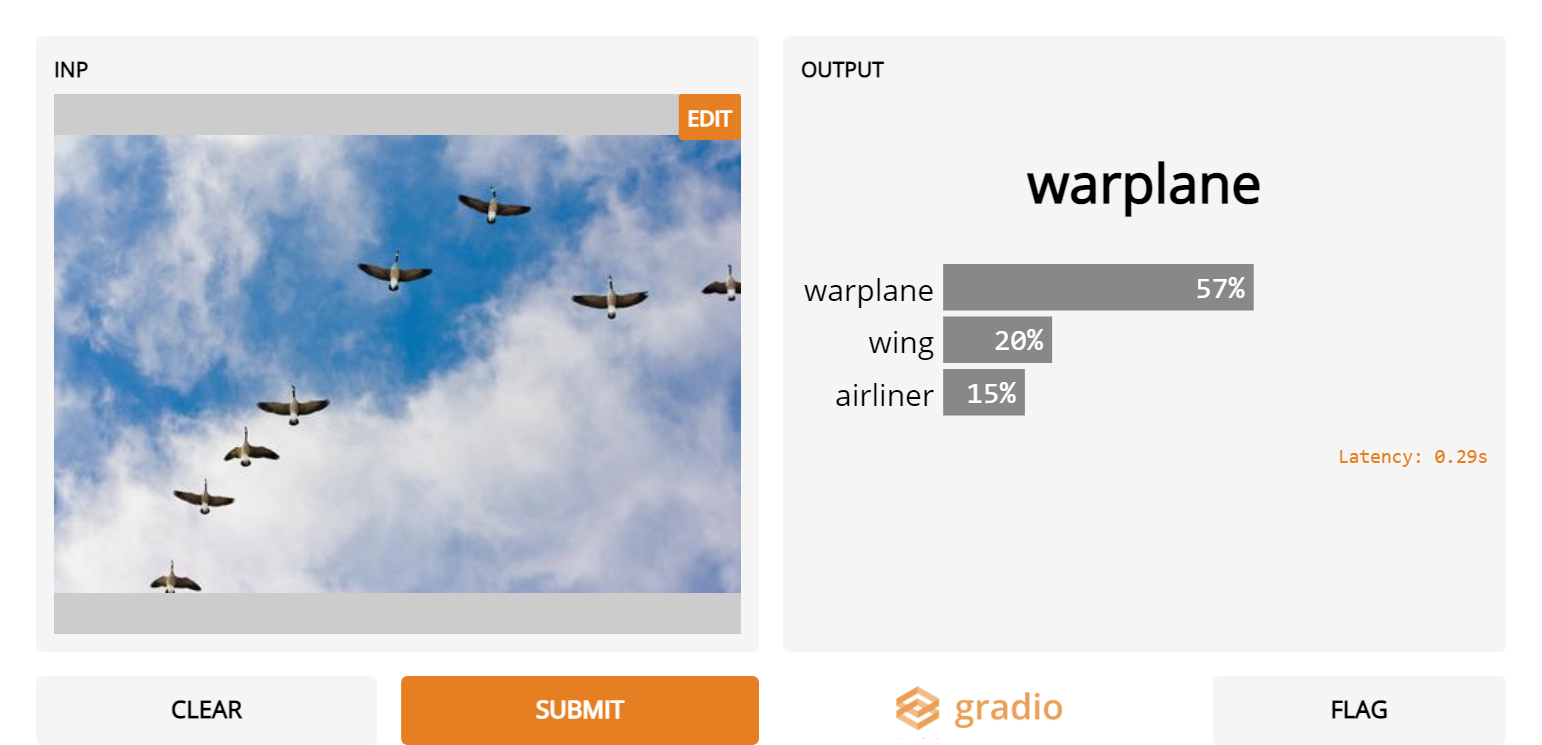
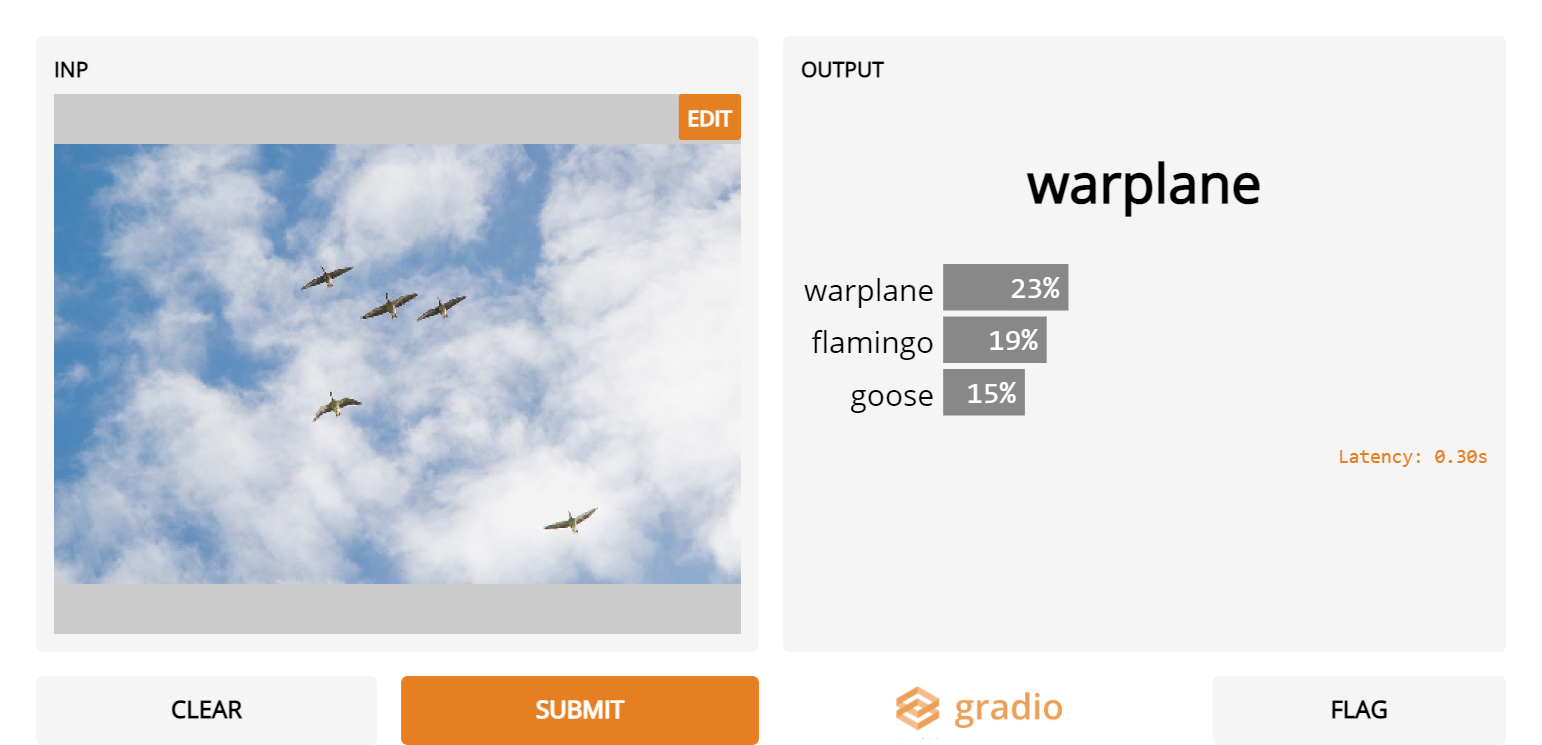
8. Geese in the Sky
- Inception Net wouldn’t be good at threat detection as it mistakes these harmless geese in the sky for warplanes!
Takeaways
So we’ve found some examples where Inception Net fails… so what? Well, deep learning-based image classifiers like Inception Net are believed to be highly accurate, to the point that many companies release them as APIs [1, 2, 3] designed to be used by the general public. The release is rarely accompanied by descriptions of failure points of the model, so users don’t really know when to expect the model to be reliable and when not to.
By simply experimenting with the model via a web interface, I found several blind spots of Inception Net: for example, objects in unusual positions (#1) or items from non-Western cultures (#3) or even images in non-standard artistic styles (#6). The Gradio library also made it easy for me try to natural image manipulations like rotations, cropping, or adding noise on my images directly through the web interface, making it easier to surface problems with the model. These failure points should be thoroughly investigated and documented so that users known when to trust deployed image recognition models.
It was really easy to try Inception Net with images that were accessible for me (I simply did Google Image searches or tried images from my computer). Try the model yourself (http://www.gradio.app/hub/abidlabs/inception) and let everyone know in the comments what other blindspots you find!
[1] https://cloud.google.com/vision
[2] https://azure.microsoft.com/en-us/services/cognitive-services/computer-vision/
[3] https://imagga.com/